Mozilla bietet einen riesigen Datensatz menschlicher Stimmen an.
Mozilla, der Hersteller des Firefox-Browsers, hat den größten Datensatz menschlicher Stimmen verfügbar gemacht, der komplett von Freiwilligen eingesprochen wurde. Mit dem Projekt "Common Voice" soll der weltweit vielfältigste Sprachdatensatz erstellt werden, der für die Entwicklung von Sprachtechnologien optimiert ist.
Das Unternehmen in San Francisco will damit vor allem kleineren Herstellern und Crowdfunding-Projekten ohne Lizenzgebühren ermöglichen, eigene Spracherkennungssysteme zu entwickeln. Bisher dominieren die großen Internetkonzerne wie Google, Microsoft, IBM, Amazon und Apple den Markt für Spracherkennung. Wichtiger Player ist außerdem das Unternehmen Nuance, dessen Technik hinter der Spracherkennung von Apples Siri steckt.
Umfang
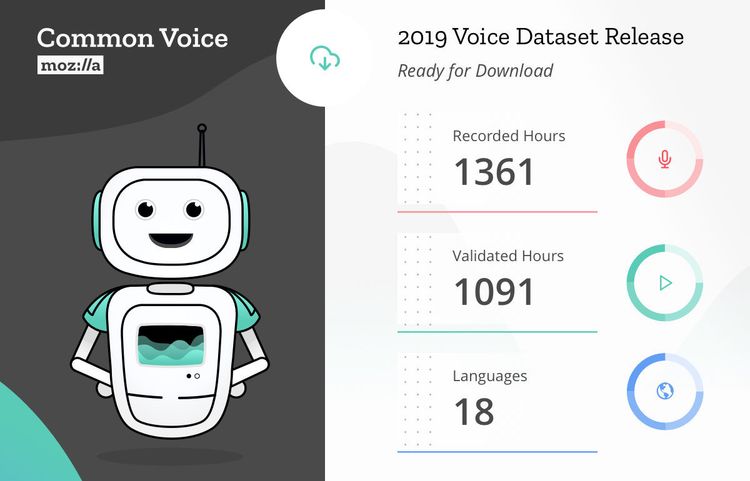
Der Datensatz von Mozilla umfasst nach Angaben des Unternehmens 18 verschiedene Sprachen, darunter Englisch, Französisch, Deutsch und Mandarin (traditionell), aber auch beispielsweise Walisisch und Kabyle, eine algerische Berbersprache. Der Datensatz summiert sich zu fast 1.400 Stunden aufgezeichneter Sprachdaten von mehr als 42.000 Mitwirkenden.
Die von Mozilla eingesammelten Daten stehen unter der "CC0"-Lizenz zur Verfügung. Das ist die freizügigste Variante der Creative-Commons-Lizenzen ("No rights reserved"). Die Projekt-Teilnehmer haben dabei freiwillig auch Metadaten wie Alter, Geschlecht und Akzent angeben. "Damit werden gemeinsam mit ihren Aufzeichnungen weitere Informationen gespeichert, mit denen Sprach-Engines noch besser trainiert werden können", heißt es in dem Blog-Eintrag von Mozilla. Man wolle "zu einem vielfältigen und innovativen Ökosystem an Sprachtechnologien" beitragen. Ziel sei es, eigene sprachgesteuerte Produkte auf den Markt zu bringen, aber auch Forscher und kleinere Akteure zu unterstützen. (APA, 28.2.2019)